3 Introduction To Experimental Design
Experiments help us answer questions, but there are also non-experimental techniques. What is so special about experiments?
One of the central features of an experiment is the treatment - a manipulation of some variable of interest that should have an effect on the response variable we are investigating. Whether you are manipulating the levels of a hormone to explore it’s impact on a cell/organ or embryo development, the concentration of a drug to explore it’s efficacy in treating a disease, or the levels of nitrogen in soil to explore the impacts on plant growth, a treatment is a deliberate manipulation.
It is also important to remember that there can be natural treatments - there may be natural variation among cells, organisms, spatial locations or gradients of some environmental variable in the environment that you can use to represent treatments.
So, to be very clear:
- Experiments allow us to set up a direct comparison among the levels or values of treatments of interest.
- We design experiments to minimize any bias in the comparison.
- We design experiments so that the error in the comparison is small.
- We design experiments to be in control, and having that control allows us to make stronger inferences about the nature of differences that we see in the response variable.
Experiments allow us to move towards making inferences about causation.
This last point distinguishes an experiment from an observational study. In an observational study we merely observe which units are in which treatment groups; we don’t get to control that assignment. This underpins the classic issue with assigning causation to correlation - in the following two examples, there is a strong association between the variables, but there has been no control/manipulation.
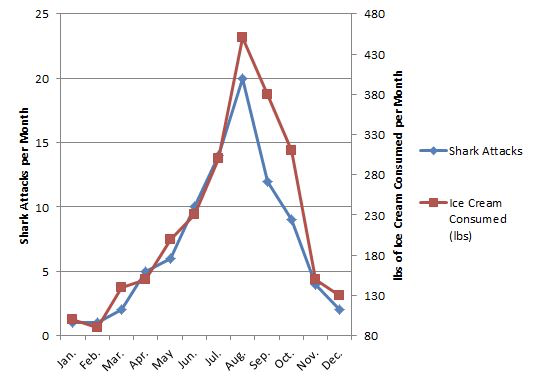
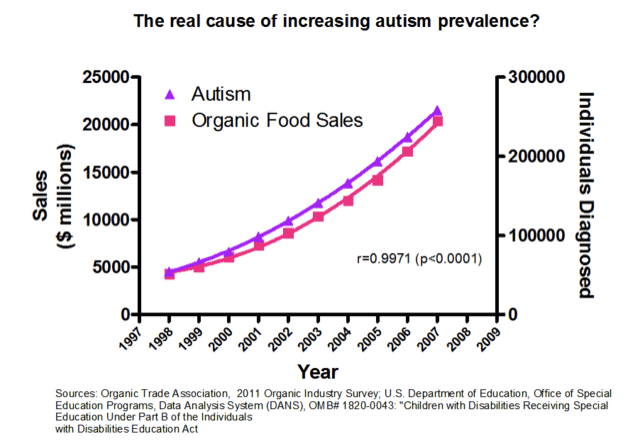
3.1 Conepts associated with causation
Mosteller and Tukey (1977) list three concepts associated with causation and state that at least two (preferably all three) are needed to support a causal relationship:
- Consistency – make a change and the response is in the same direction or the amount of response is consistent across populations
- Responsiveness – make a change and the response changes according to theory
- Mechanism – make a change and we can monitor/identify a mechanism leading from cause to effect
Let’s look at a classic example. Smoking and lung cancer – from 1922 to 1947 annual deaths for lung cancer went from 612 to 9287 (Observation). This was thought in the 1950s to be either an effect of smoking tobacco or atmospheric pollution (Hypothesis). Numerous studies showed that lung cancer was more prevalent in smokers (Observation: consistency). Chemical analyses of tobacco showed it contained carcinogens (Association: mechanism). Public health programs resulted in a reduction in smoking and lung cancer rates decreased (Intervention: responsiveness).
Note the initial study was an observational study and in this case it was not ethical to do the experiment per se!
3.2 Components of an Experiment
An experiment has treatments, experimental units, responses, and a method to assign treatments to units. These four things specify the experimental design.
Not all experimental designs are created equal. A good experimental design must adhere to the 3Rs. It should reveal consistency, responsiveness and mechanism. The way this happens is by avoiding systematic error in measuring things, and allow estimation of error in measurements with precision.
3.2.1 The holy grail of a control
At this point, it would be very good to revisit the APS 240 sections on controls and procedural controls
3.3 So what does a good experimental design do?
In short, a good experimental design must:
- Avoid systematic error
- Allow estimation of error
- Be precise
- Have broad validity.
Lets walk through some definitions.
If our experiment has systematic error, then our comparisons will be biased, no matter how precise our measurements are or how many experimental units we use. Randomisation is our tool to combat systematic error.
Even without systematic error, there will be random error in the responses - this is what we call variation in what we are measuring or more formally variance. Such variation in responses invariably leads to random error in the treatment comparisons. When we compared two means in the t-test, we had to deal with the variation in both groups!
Experiments are precise when this random error in the treatment comparisons is small. Precision depends on the size of the random errors in the responses, the number of units used (replication), and the experimental design used.
Experiments must be designed so that we have an estimate of the size of random error. This permits statistical inference: for example, confidence intervals (which arise from standard errors) or tests of significance based on t- or F-statistics.
We cannot do inference without an estimate of this variation. We would like our conclusions to be valid for a wide population, so we need to randomise our subjects or objects we are measuring - for example, we may need to be aware of both sexes and of young and old individuals. But there are always compromises - for example, broadening the scope of validity by using a variety of experimental units may decrease the precision of the responses.
3.4 How do we increase precision and reduce bias?
There are several key concepts
3.4.1 Blinding
Blinding occurs when the evaluators of a response do not know which treatment was given to which unit. Blinding helps prevent bias in the evaluation, even unconscious bias from well-intentioned evaluators. Double blinding occurs when both the evaluators of the response and the (human subject) experimental units do not know the assignment of treatments to units. Blinding the subjects can also prevent bias, because subject responses can change when subjects have expectations for certain treatments.
3.4.2 Placebos
Placebo is a null treatment that is used when the act of applying a treatment— any treatment — has an effect. Placebos are often used with human subjects, because people often respond to the process of receiving any treatment: for example, reduction in headache pain when given a sugar pill. Blinding is important when placebos are used with human subjects. Placebos are also useful for nonhuman subjects. The apparatus for spraying a field with a pesticide may compact the soil. Thus we drive the apparatus over the field, without actually spraying, as a placebo treatment.
3.4.3 Confounders
Confounding occurs when the effect of one factor or treatment cannot be distinguished from that of another factor or treatment. The two factors or treatments are said to be confounded. Except in very special circumstances, confounding should be avoided. Consider the following example. We plant corn variety A in Yorkshire and corn variety B in Lancashire. In this experiment, we cannot distinguish location effects (Yorkshire vs. Lancashire) from variety effects (cornA vs. cornB) — the variety factor and the location factor are confounded.
This is despite the fact that we know that Yorkshire will be better…. (that is a joke)
3.5 Experimental vs. Measurement units
A common source of difficulty in designing experiments is the distinction between experimental units and measurement units. We need to know the experimental units, as this is the key value used to generate our inference.
Now is a good time to re-look at the short section on Jargon Busting from the APS 240 book.
3.5.1 Experimental and measurement units: an example
Consider an educational study, with six classrooms of 25 pupils. Each classroom of students is then assigned, at random, to one of two different reading programmes.
At the end of a six-week term, all the students are evaluated via a common reading exam.
The challenge question
Are there six experimental units (the classrooms) or 150 (25*6; the students)? We measured the reading ability of the students… but they were in classroom sets of 25….
3.5.2 Identifying the experimental unit - an example of pseudo-replication
To identify the experimental units the key question is: To which thing (students or classrooms) did we randomly allocate our treatments?
If we randomly allocated reading programmes to students, then students would be the experimental units. But we didn’t, so the classroom is the experimental unit – it is the classroom to which we randomly allocated treatments.
The classroom is the experimental unit.
However, you are right - we don’t measure how a classroom reads; we measure how students read. Thus students are the measurement units for this experiment.
3.5.3 Psudo-replication
Confusing these two things can lead to pseudo-replication. Treating measurement units as experimental usually leads to overoptimistic analysis — we will reject null hypotheses more often than we should, and our confidence intervals will be too narrow. The usual way around this is to determine a single response for each experimental unit.
There is additional information on Independence and Pseudoreplication in the the APS 240 book.
3.5.3.1 Independence: an example
Consider an experiment with two growth chambers each containing 100 plants. One of the chambers received enhanced C02. One night after collecting data you leave the door open on the C02 chamber and the temperature drops and so the plants grow more slowly. When you come to analyze the data you get a highly significant effect of slow growth. However, that C02 results in reduced plant growth not what you expect (CO2 is good for photosynthesis…).
This is an entirely plausible outcome caused by misallocating plants as the experimental unit - it was really the CO2 chamber… to avoid such problems, one needs many chambers.
Consider a second experiment where you have 200 growth chambers and randomly allocate plants to each. If you forget to close one door it really has no effect as just one plant is affected. In fact, to get the same effect as in the first experiment you would have to accidentally leave the doors open on all 100 of the elevated C02 chambers. This is very unlikely indeed!!!
There are 9 x 1058 ways selecting 100 chambers from 200 chambers so the chance of accidentally picking all the elevated C02 chambers is 1/ 9x10580 (stars in universe 7 x 1022).
Proper randomization and replication is very different from pseudo-replication.
3.5.4 Randomization with Replication protects against Confounding
An experiment is properly randomized if the method for assigning treatments to units involves a known, well-understood probabilistic scheme. The probabilistic scheme is called a randomization.
In general, more experimental units with fewer measurement units per experimental unit works better.
No matter which features of the population of experimental units are associated with our response, our randomizations should put approximately half the individuals with these features into each treatment group.
Recall our example above of considering sex and age of subjects and imagine a treatment with two levels (hot and cold). Done well, proper randomisation will put approximately half the males, half the females, half the older, half the younger etc into each of the treatment levels.
The beauty of randomization is that it helps prevent confounding, even for factors that we do not know are important.
3.5.5 Haphazard is NOT randomized - beware the non-randomized experiment
A company is evaluating two different word processing packages for use by its clerical staff. Part of the evaluation is how quickly a test document can be entered correctly using the two programs. We have 20 test secretaries, and each secretary will enter the document twice, using each programme once.
Suppose that all secretaries did the evaluation in the order A first and B second. The haphazardness here is chooseing to evaluate A first and B second, perhaps by a coin-toss. But does the second programme have an advantage because the secretary will be familiar with the document and thus enter it faster? Or maybe the second programme will be at a disadvantage because the secretary will be tired and thus slower?
Randomization generally costs little in time and trouble, but it can save us from disaster. The experiment above needs secretaries randomly assigned to A first -> B second and B first -> A second (50% in each!).
Anything that might affect your responses should be randomized! For example
- If the experimental units are not used simultaneously, you can (should) randomize the order in which they are used.
- If the experimental units are not used at the same location, you can (should) randomize the locations at which they are used.
- If you use more than one measuring instrument for determining response, you can (should) randomize which units are measured on which instruments.
3.6 Mini-Quiz
A PhD student want to determine the effects of protein on beetle reproduction, so they design an experiment with a control and protein enhanced diet. To assign beetles to each of the treatments they pour a culture onto the table and catch the first 30 beetles that run to the edge of the table, these receive the protein enhanced diet. The next 30 beetles go in the control. Is this randomized?
(Hmm …. is there anything about the first 30 beetles that reach the edge of the table that could bias your inference?)
3.7 Replication: How many?
There is a really common question that people ask. How many replicates do I need? Unfortunatly, there are no simple rules… it depends… on….
- Resources available ($/£/€ and equipment and time)
- Variability of experimental units
- Treatment structure
- Size of effect (response)
- Relative importance of different comparisons
There is, however, a set of tools that can help with estimating sample sizes. It’s called power analysis and requires that you have some a priori estimate of the expected variation in your response variable.